
Most teams building Retrieval-Augmented Generation (RAG) systems follow the same playbook: chunk the data, generate embeddings, store them in a vector database, and connect everything to an LLM. On paper, it’s a solid pipeline. In practice, something feels off.
The answers aren’t wrong, but they’re not quite right either.
This gap is often blamed on the language model. But the real issue usually lies upstream. When your system retrieves context that is only loosely relevant, or worse, subtly misleading, even the most advanced LLM can’t produce high-quality answers. This hidden failure mode, often called vector washout, stems from the limitations of embedding-based retrieval, where nuance, negation, and intent are lost in translation.
In this blog, we’ll unpack why traditional vector search struggles with true relevance, and how a simple yet powerful upgrade – cross-encoder re-ranking in RAG can dramatically improve the quality of your RAG pipeline. If your system is retrieving “similar” content but still missing the point, this is the fix you’ve been looking for.
The Retrieval Problem Nobody Tells You About
You’ve done all the right things, in theory. You have chunked your documents, created embeddings, set up a vector database, and hooked it up to a large language model (LLM). The pipeline looks solid. But then users start complaining. The responses are good but not great.
Developers typically point the finger at the LLM. This is usually not the case. It’s actually a source grounding problem, but the system is retrieving the wrong documents and using them as context. If the evidence you’re feeding your LLM is poor, you’re going to get poor results, whether you’re using GPT-4o or a fine-tuned Llama 3. This is a particular problem called vector washout.
The typical embedding models reduce whole paragraphs to a single vector. In the process, important language features like “not”, “except”, and negation are lost. They don’t even make it to the model. Using a better LLM won’t solve the problem. It’s not the model. It’s the messy context. The solution is to improve the selection of documents and that’s where cross-encoder re-ranking in RAG comes in.
What Standard Retrieval Actually Does (And Where It Breaks Down)
Traditional RAG retrieval is based on vector similarity search:
- It turns your query into a vector (embedding).
- It then calculates the distance (typically cosine similarity) between that vector and all your pre-calculated document chunk vectors.
- The most similar documents are fed to the LLM. This is efficient and scalable, but it’s not quite right: it’s topical overlap, not logical relevance.
Embeddings are lossy by design. They reduce an entire paragraph to a single vector, throwing out the subtle word-to-word relationships that often determine whether a document is relevant.
For Example, a document titled “How to Cancel a Flight” and a document titled “Flight Cancellation Policy” might be very similar in vector space – but one is an instruction manual and the other is a disclaimer. Traditional retrieval can’t distinguish between a document that contains your keywords and a document that answers your question.
Bi-Encoders vs Cross-Encoders
To understand why cross-encoders are so much more effective, you need to understand what bi-encoders fundamentally cannot do. Here’s a brief difference between bi-coders vs cross-encoders.
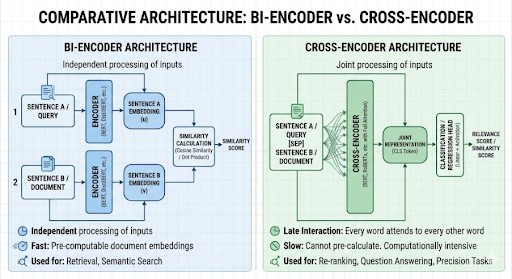
Bi-Encoders
Query [Encoder] Vector u
Doc [Encoder] Vector v
Score = fu, v e.g., Cosine Similarity or Dot Product
Bi-Encoders encode the query and each document independently. They are encoded into a vector, and the relevance is assessed later by comparing the vectors. This means the model can only judge whether the query and the document are about the same topic or “vibe” – not whether the document is a good answer to the query.
mattis, pulvinar dapibus leo.
Cross-Encoders
[Query + Document] -> [Cross-Encoder] -> Relevance Score
Since both pieces of text are fed through the entire attention mechanism, each word in the query can interact with each word in the document.
This is known as late interaction, and it’s what gives cross-encoders their superior ability to understand nuance.
A cross-encoder can tell that you are looking for a deadline, but the document you have found only talks about procedures, and it can push it down the rankings, even though the keywords look like a good match.
Four Reasons Cross-Encoders Get it Right
- Negation Handling: Bi-encoders perform poorly with sentences such as “Employees can submit expenses” vs. “Employees cannot submit expenses” – the overlap in words is 95%. Cross-encoders treat both sentences as one and understand the contradiction.
- Answer Type Matching: If a user wants to know the date of an event, a bi-encoder may return a policy document that has something to do with the event. A cross-encoder recognises the type of answer needed and ranks chunks that contain dates or time periods.
- Vocabulary Bridging: If a user asks about “tummy pain” and the document mentions “abdominal discomfort”, the cross-encoder’s joint attention mechanism knows this is a medical connection much more confidently than two separate embeddings.
- Chunking Artifact Reduction: If an answer is chunked, a bi-encoder might consider the fragment to be noise because it doesn’t have independent topical relevance. A cross-encoder can still identify its relevance to the query on its own.
Also read: Understanding Embeddings: The Backbone of Modern AI Retrieval Systems
Creating the Two-Stage Pipeline
The answer is a waterfall approach: use a bi-encoder to quickly get the top 20-50 documents from your corpus, then use a cross-encoder to get the top 3 from that subset. It’s like a fishing net and a microscope.
Install the dependencies:
pip install sentence-transformers scikit-learn numpy
The implementation:
from sentence_transformers import SentenceTransformer, CrossEncoder
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
class TwoStageRetriever:
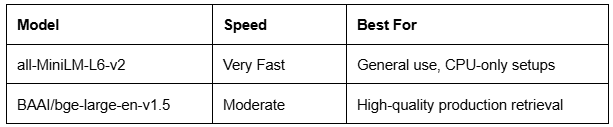
def __init__(self, bi_model='all-MiniLM-L6-v2',
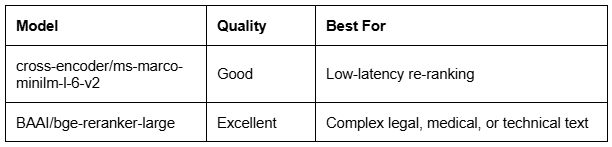
cross_model='cross-encoder/ms-marco-MiniLM-L-6-v2'):
self.bi_encoder = SentenceTransformer(bi_model)
self.cross_encoder = CrossEncoder(cross_model)
self.documents = []
self.doc_embeddings = None
def index(self, documents):
self.documents = documents
self.doc_embeddings = self.bi_encoder.encode(
documents, show_progress_bar=True)
def search(self, query, top_k=10, top_n=3):
# Stage 1: Bi-Encoder (fast retrieval)
q_emb = self.bi_encoder.encode([query])
sim_scores = cosine_similarity(q_emb, self.doc_embeddings)[0]
top_k_indices = np.argsort(sim_scores)[::-1][:top_k]
candidates = [self.documents[i] for i in top_k_indices]
# Stage 2: Cross-Encoder (precise re-ranking)
pairs = [[query, doc] for doc in candidates]
rerank_scores = self.cross_encoder.predict(pairs)
ranked = sorted(zip(rerank_scores, candidates),
key=lambda x: x[0], reverse=True)
for i, (score, doc) in enumerate(ranked[:top_n], 1):
print(f'#{i} [Score: {score:.4f}] {doc}')
return ranked[:top_n]
# Example usage
docs = [
'Employees should submit travel expenses within 30 days of return.',
'All expense claims must have a valid receipt of over $25.',
'Self-approval of expense reports is strictly forbidden.',
'Travel insurance is covered for international trips only.',
'Managers must approve all team expenses via the portal.'
]
retriever = TwoStageRetriever()
retriever.index(docs)
retriever.search('Can I approve my own travel expenses?')
The Speed Trade-Off (And Why It’s Not Actually a Problem)
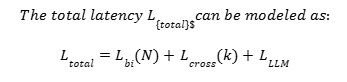
The typical complaint about cross-encoders is speed. It would take hours to run one over a million documents. But in a two-stage system, you’re only re-ranking 20-50 documents, not every document. That means less than 100ms of extra time. But think about what you get for that overhead: in a RAG system where LLM inference takes 2-5 seconds, 100ms to get a much better context is negligible. With techniques such as Flash Attention and INT8 quantization, this can be even lower.
Choosing the Right Models
Stage 1 — Bi-Encoders (Speed & Recall)
Stage 2 — Cross-Encoders (Precision & Logic)
The Bottom Line
RAG retrieval measures topical relevance. Cross-encoder re-ranking in RAG measures answer relevance. These are not the same thing – and it’s the difference that leads to hallucinations. With just 15 more lines of code, you go from finding related text to finding the right answer. A good bi-encoder will get you to the right part of town; a good cross-encoder will get you to the right house. If you feed your LLM better evidence, it will answer your users’ questions. It’s that simple.
If you’re building RAG systems or exploring agentic AI, keep following us. We share practical insights like this, and build AI agents for customer service, sales, and engagement that actually work in production.


