
In the last few years, embeddings have become one of the most essential building blocks in AI systems, most especially in Search, Recommendation Engines, and Retrieval-Augmented Generation, or RAG. If you have worked with semantic search, vector databases, or LLM-powered assistants, you have already relied on embeddings, whether you know it or not.
In this blog, we’ll break down:
- What embeddings really are
- Sparse vs Dense Embeddings
- How Embedding Retrieval Works
- What embedding-based retrieval means in practice
- What are embeddings in RAG
What are Embeddings?
Talking generally, embedding can be referred to as a numeric form of data representation. The data that can be embedded could be texts, images, or code. Embeddings convert words, sentences, or documents into numerical vectors, allowing computers to understand relationships. For example, embeddings can be used to recognize that “dog” and “puppy” are related.
When we represent text using word embeddings:
Each sentence, document, or paragraph is represented as a vector of numbers.
These vectors are able to detect meaningful information rather than just keywords. Hence, the more similar in meaning → the closer the vectors will be in the vector space.
For example:
“How to reset my password.”
“I forgot my login credentials.”
Although their representations have a different wording, they will be close to each other in embeddings. This is what makes the semantic understanding possible, not just the keyword matching.
Sparse vs Dense Embeddings: What’s the Difference?
Sparse Embeddings
Sparse embeddings are high-dimensional vectors where most values are zero, and only a few dimensions may contain non-zero entries. In applications in text, each dimension may represent an explicit word, phrase, or token-so the vector reflects the presence or weight of particular terms in the document or query directly.
Key Features:
- Most entries are zero; only a few dimensions are nonzero.
- Dimensions map to explicit features such as individual words, hence dimensions are very interpretable – you can tell exactly which features are contributing to similarity.
- They work well when there’s an exact keyword or entity match involved, for example, classic search engines or specialized domain jargon.
- Often utilize inverted files – e.g., TF-IDF or BM25 – to achieve very fast retrieval.
- However, sparse embeddings inherently do not capture semantic relationships-for example, “car” and “automobile” might have completely orthogonal vectors even though they are related in meaning.
Examples/Use Cases:
- TF-IDF vectors
- One-hot term representations
While the state-of-the-art sparse retrieval models learned, such as SPLADE, combine lexical and semantic features, they are a modern evolution of sparse approaches.
Dense Embeddings
Dense embeddings are continuous, lower-dimensional vectors where almost every element is non-zero. Each dimension represents some semantic meaning, and the vector as a whole represents the content in a compact, distributed form. These embeddings are usually produced from deep neural network models such as transformer encoders or contrastive representation models.
Dense embeddings seek to convert the high-level semantic meaning of text into numbers. Unlike traditional representations, which consider each term independently, dense embeddings blur every dimension with significant values, enabling similar items to group in vector space according to semantic meaning.
Key Features:
- Lower-dimensional (e.g., 512 or 768)
- Continuous values with few to no zeros
- Focus on semantic meaning and context, not exact words
- Computed using neural models such as BERT, GPT, ELMo, or embedding models
Example Applications:
- Semantic search
- Document similarity and clustering
- RAG retrieval
- Recommendation systems
- With dense embeddings, systems can relate similar content even if they use different vocabulary, which is a major requirement in today’s AI-powered search applications.
Best Models for Sparse vs Dense Embeddings
There is no single “best model” that works for all applications, but there are a few popular and highly successful models that you should be aware of:
Best Sparse/Lexical Retrieval Models
Sparse retrieval is not just limited to traditional TF-IDF; there are now learned sparse models too:
- BM25 or TF-IDF: traditional sparse models for keyword weighting.
- Learned sparse models like SPLADE (and SPLADE v2): leverage term matching and neural understanding for competitive performance.
Best Dense Embedding Models (for semantic retrieval)
These models learn to represent text as dense vectors that are optimized for semantic meaning:
- OpenAI Embedding Models (such as Ada / more recent embedding models): popular for dense semantic similarity in RAG models.
- E5 Family: high-quality open-source dense text embedding models for retrieval (leaderboarded by the community).
- Sentence Transformers (BERT variants): great for embedding sentences and paragraphs.
- LaBSE: a multilingual dense embedding model for cross-lingual retrieval.
These dense models are highly successful for embedding retrieval applications where semantic meaning is the primary goal.
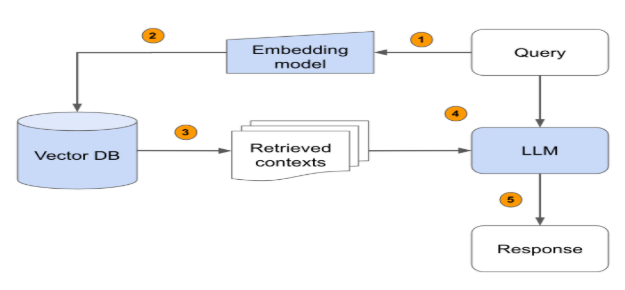
Embedding-Based Retrieval: How It Works
Embedding-based retrieval is a way of retrieving relevant information by comparing embeddings instead of text. Here is how it works:
- Transform documents into embeddings
- Store them in a vector database
- Transform the user query into an embedding
- Find the closest vectors using similarity measures (cosine similarity, dot product, and so on)
- Return the most semantically similar results
- Unlike keyword search, embedding-based retrieval is based on intent and context, not words.
Embedding Retrieval vs Traditional Search
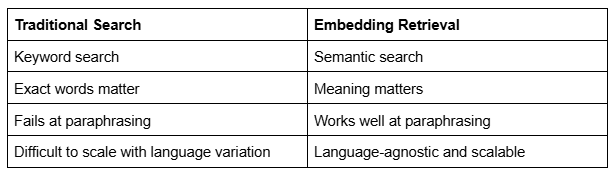
This is why modern AI systems favor embedding retrieval over traditional search methods.
What Are Embeddings in RAG?
To answer the question of what embeddings are in RAG, we have to examine the process of RAG systems.
RAG (Retrieval-Augmented Generation) Flow
- User asks a question
- The question is transformed into an embedding
- Relevant documents are retrieved using embedding-based retrieval
- The retrieved information is added to the LLM prompt
- The LLM produces a grounded and correct answer
Why Embeddings Are Essential in RAG?
- They are the link between user queries and external knowledge
- They prevent hallucinations by linking answers to the retrieved information
- They enable RAG systems to handle millions of documents
- Without embeddings, RAG systems would not function properly.
Best Embedding Model for Retrieval: What to Look For
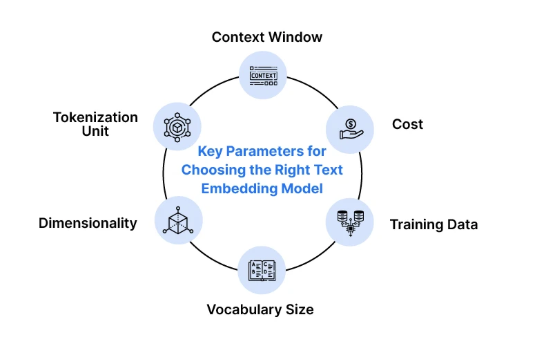
The best embedding model for retrieval depends on your application, but there are some general guidelines:
Key Factors That Affect the Selection:
- Semantic accuracy: They should convey meaning, not syntax
- Dimensional efficiency: Fewer dimensions mean faster search
- Domain adaptability: They should work well on your dataset (finance, law, healthcare, etc.)
- Multilingual support (if required)
- Latency & cost: More important in production environments
Conclusion
Embeddings are the foundation of modern retrieval and RAG systems, enabling AI to understand intent, context, and meaning beyond keywords. From sparse lexical approaches to dense semantic embeddings, the right retrieval strategy is essential for building scalable and reliable AI applications.
Exei is an Agentic AI platform that builds and deploys AI Agents for customer service. It helps businesses automate support, engage customers across channels like websites, WhatsApp, Instagram, and more, and deliver personalized, 24/7 conversational experiences.
To learn more about intelligent AI agents and automate your customer support & streamline operations, contact us at Exei.ai.


